

1. Kafka Architecture
1.1 Brokers
A Kafka broker is a server that stores messages and serves client requests.
- Producers send data to brokers.
- Consumers fetch data from brokers.
- Brokers manage topics and partitions.
Each broker can handle thousands of partitions and millions of messages per second. A Kafka cluster is typically made up of multiple brokers for scalability (spreading the load) and resilience (no single point of failure). Example: In a three-broker cluster, a topic with six partitions might be distributed so that each broker manages two partitions.
1.2 Log Files and Structure
When people say “Kafka is a distributed log,” they mean it literally. Kafka stores data in log files on disk, and the way these logs are structured is the secret to its performance and reliability. Each partition in Kafka corresponds to a log file on disk.
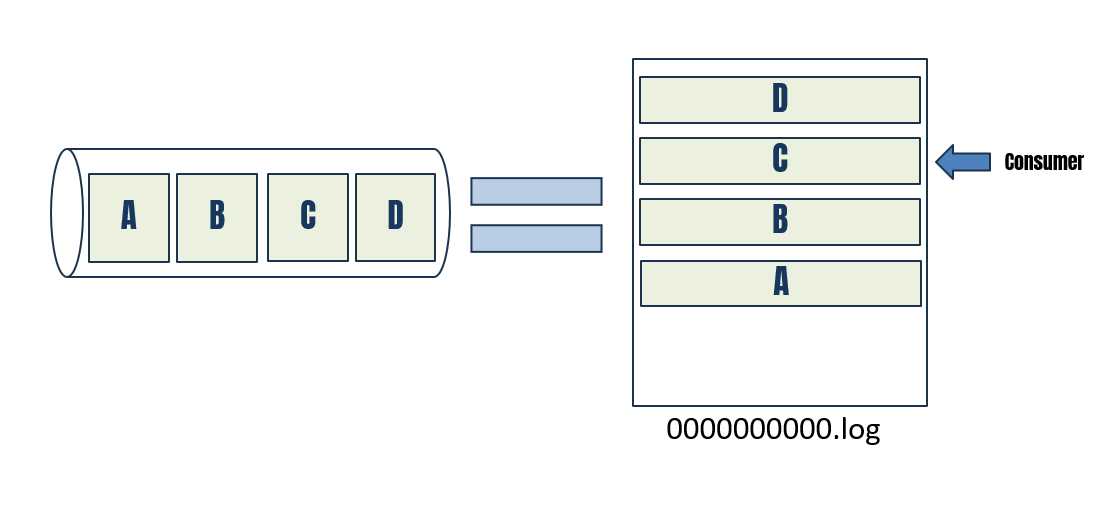
- This log file is an append-only commit log, meaning you can only append new data to the end of the file and cannot remove or overwrite already stored records.
- New messages are written at the end of the file.
- Each message is assigned a unique, ever-increasing offset.
Each log entry typically contains:
- Offset – a unique ID for ordering within the partition.
- Message size – how many bytes the record occupies.
- Message payload – the actual data.
- Metadata – such as a timestamp and checksums for validation.
1.3 Consumer Offsets
Kafka doesn’t delete messages once a consumer reads them. Instead:
- Each consumer group maintains its own record of offsets. This means multiple consumer groups can read the same topic independently without interfering.
- If a consumer crashes, it can restart and resume at the last committed offset.
Offsets are stored in an internal Kafka topic (__consumer_offsets), which allows the cluster to keep track of every group’s progress reliably. This design is what makes Kafka both a queue (messages processed once per consumer group) and a publish–subscribe system (multiple groups can consume the same data). Example: Suppose a producer writes a message to partition 2 of the orders topic. Kafka appends it to the active log segment and assigns it offset 105. The consumer group order-processing has committed its last read offset as 104. When the consumer fetches again, Kafka delivers offset 105 onward. Meanwhile, another group, analytics, may still be reading from offset 90 independently.
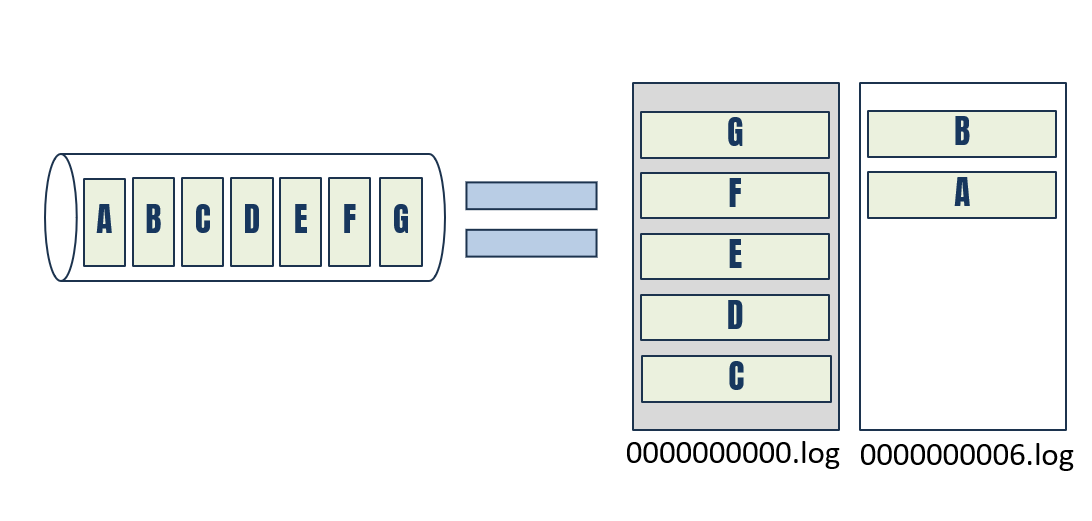
1.4 Segments in Log Files
Kafka doesn’t keep one giant file for each partition. Instead, each partition’s log is split into segments (smaller files) on disk.
- A segment is typically a few megabytes to gigabytes in size (configurable).
- When a segment is full, Kafka closes it and starts writing to a new one.
- Each segment is named by the offset of its first message.
This segmentation makes log management efficient: old segments can be deleted or compacted without touching active ones.
1.5 Retention and TTL
Unlike traditional queues, Kafka doesn’t erase messages once they are consumed. Messages remain on disk until their retention policy is triggered. You can configure:
- Time-based retention (TTL) – for example, keep messages for seven days.
- Size-based retention – for example, keep up to 500 GB of logs.
- Infinite retention – messages are never deleted, so Kafka acts like a permanent log store.
This means consumers can re-read old messages or even rebuild state from scratch if needed.
1.6 Leaders and Leader Election
Each partition has a leader replica and one or more follower replicas.
- The leader handles all reads and writes.
- Followers replicate the data for fault tolerance.
- If the leader fails, Kafka performs a leader election and promotes one of the followers.
This guarantees high availability and prevents data loss. Traditionally, Kafka used Zookeeper to keep track of cluster metadata (for example, broker membership and leader election for partitions). However, modern Kafka versions (2.8+) can run without Zookeeper thanks to the KRaft (Kafka Raft) protocol, which simplifies operations.
2. Takeaway
Kafka’s true strength lies in its log-based architecture:
- Append-only commit logs provide durability.
- Consumer-managed offsets enable replay and resilience.
- Segmented log files keep storage efficient.
- Retention policies let you balance cost and reprocessability.
- Leader election ensures high availability.





